代码编辑器是如何工作的?(上)
什么是代码编辑器?
根据维基百科 Source-code editor 词条的描述
A source-code editor is a text editor program designed specifically for editing source code of computer programs.
也就是说,一部分代码编辑器是专门为代码这种文本文件进行设计的 “文本编辑器”:
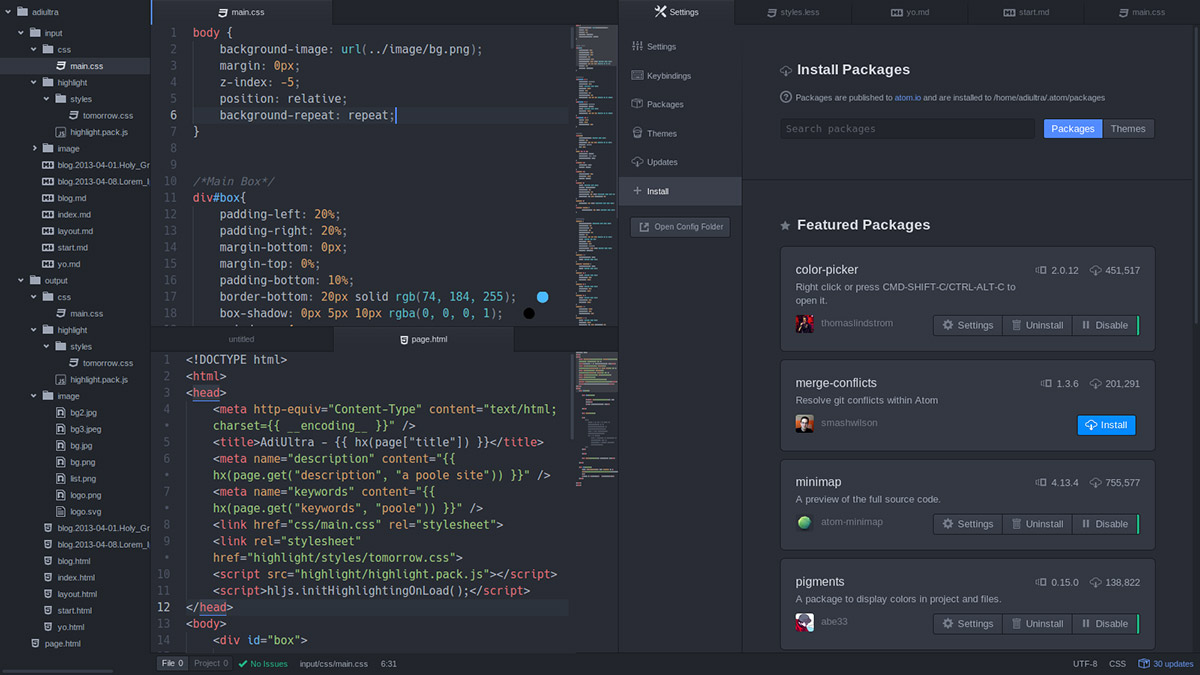
还有一部分代码编辑器是“结构化编辑器”,例如 Stratch 语言的编辑器等,用户能够通过例如拖拽等方式来直接对代码的 结构 进行操控:
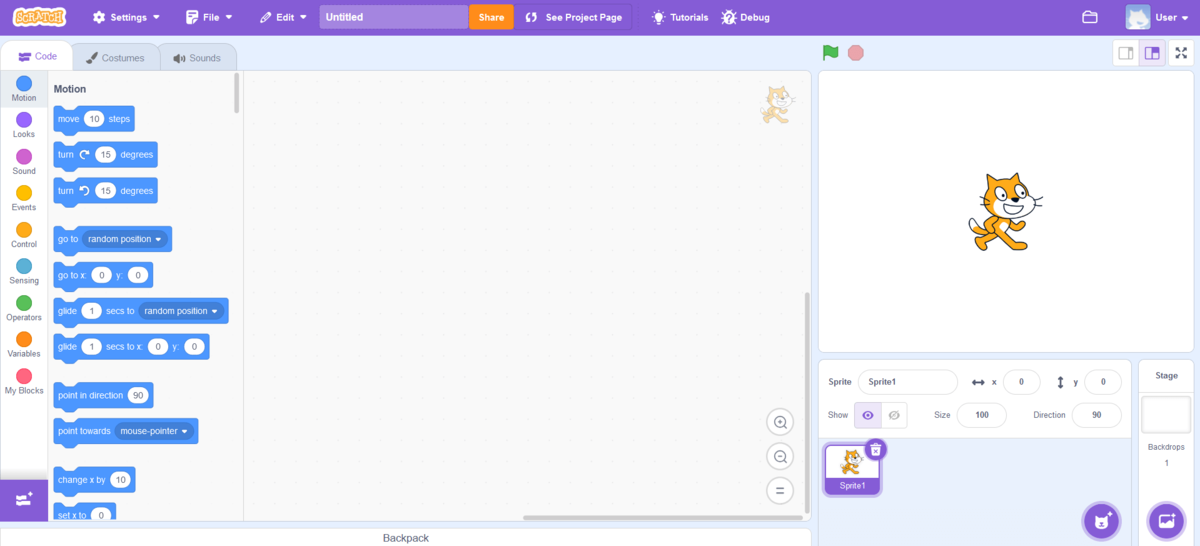
虽然结构化编辑器的概念非常不错,但我们今天并不会讨论结构化编辑器
那么,什么是文本编辑器?
要回答这个问题,我们需要先弄清楚两个简单的问题:
- 什么是“文本”?
为了方便理解,我们在这里给出一个非正式的定义:
文本是某种由一系列由某种编码决定的字符以及可能的一些额外信息组成的数据。在没有这些额外信息的情况下,我们把它们叫做平文本(Plain Text),这也是代码编辑器所需要支持的文本形式。
- 什么是“编辑”?
编辑(或者说所见即所得式的编辑),必须满足以下两点
- 用户能够看到编辑的内容:即编辑的内容能够展示到屏幕上
- 用户能够与编辑的内容进行交互:即用户能够通过某些操作来修改编辑的内容
也就是说,能够支持对“文本”进行展示以及交互的东西,我们就可以叫它文本编辑器。
但文本编辑器和文本编辑器是不同的,下面这些东西我们都可以把它们叫做文本编辑器:
- 记事本
- Microsoft Word
- HTML 里的
textarea - Visual Studio Code
作为 代码编辑器 的文本编辑器和其它文本编辑器的区别在哪?
- 编辑的内容是 Plain Text,且编辑是所见即所得的
- 文本在展示给用户时可能会包含很多额外的信息
- 编辑行为产生的效果可能会和上下文有关
- 在编辑大量文本时仍然能够及时响应
- ……
在《代码编辑器是如何工作的?(上)》中,我们将着重讲解代码编辑器作为文本编辑器的功能。
文本编辑器是如何工作的?
字符编码
用户与编辑器的交互最终都会变成对于文本数据的 CRUD,考虑到之前我们对于“文本”的定义,我们必须先知道什么是 “字符” 和 “字符编码”
在电脑和电信领域中,字符(Character)是一个信息单位。对使用字母系统或音节文字等自然语言,它大约对应为一个音位、类音位的单位或符号。简单来讲就是一个汉字、假名、韩文字……,或是一个英文、其他西方语言的字母。
而为了让由这些字符组成的文本能够在计算机里进行存储、传输,我们必须定义一套规则将这些字符转化为基于二进制表示的数据。
这套规则统称为 字符编码。
Unicode Character Encoding Model 将现代字符编码模型分为 5 个层次:
-
抽象字符表(Abstract Character Repertoire):语言系统支持的所有抽象字符的集合
例如:Latin-1(CS 00697)/POSIX 跨平台字符表/Windows 西欧字符表/Unicode 10646 字符表 等,而抽象字符会拥有一个独一无二的名字,例如 LATIN SMALL LETTER A
-
编码字符集(Coded Character Set):字符表中的字符 到 一些非负整数的集合 的映射。这个集合被称为码空间,其中的元素被称为码位(code point)
例如 ISO/IEC 8859-1 与 ISO/IEC 8859-2 使用了不同的字符表,但拥有相同的码空间
-
字符编码表(character encoding form):将编码字符集里的码位转换成 由“固定长度的整数组成的序列” 的方式,这些具有固定位宽限制的整数被称为码元(code unit)
例如 UTF-8 中使用了 8 位长的码元作为字符的数据基础表示形式,而它会对 0~0x10fff 的数字分别转化为 1~4 个码元,而 UTF-16 会使用一个 16 位整数来表示码元
-
字符编码方案(character encoding scheme):将码元映射到字节的序列以进行文件存储和传输的方案
对于简单字符编码方案,它们提供了从码元到字节序列的直接映射方案,例如 UTF-8;而对于复合字符编码方案, 可能由多个简单字符编码方案组成,方案需要提供在字节序列中标明编码方案的方式,例如 UTF-16 会在数据开头添加一个可选的 byte order marker(BOM )来表示使用 UTF-16LE 或者 UTF-16BE
-
传输编码语法(transfer encoding syntax):将字符编码方案里的数据进行进一步处理的方式
例如 Base64 可以把 8 位的字节数据编码为 7 位的数据,而采用某些无损压缩算法能使文本数据的量减少
值得一提的是,在早期 Unicode 标准中,code point 的合法值仅为 U+0000 ~ U+FFFF;而在一次标准修订中,code point 的范围被扩充到 U+0000 ~ U+10FFFF,此时的 code point 也被叫做 Unicode scalar value,而原本的范围被称为 Basic Multilingual Plane。在扩充的过程中原本的 code point 里被添加了 Surrogate 机制来支持使用两个 16 位整数来表示一个大于 U+FFFF 的 Unicode scalar value
也就是说,在任何需要和文本数据打交道的行为中,都需要考虑一个问题:我需要处理的文本编码是什么?在回答了这个问题之后我们才能够从文本数据中解析有意义的数据。
对于文本编辑器而言,可能需要处理的文本文件使用的编码是多种多样的:例如用于进行中文文本表示的 GB2312/GBK/GB18030 标准中规定的编码,或者是 Unicode 标准中使用的 UTF-8 编码。
但编辑器并不可能对于所有的编码单独实现一套数据结构进行编辑过程中的 CRUD,所以对于编辑器而言,也需要一套编码用于它所需要维护的数据。这个选择一般会从以下几个角度进行考量:
- 实现难度:UTF-32 只需要使用一个 32 位整数就可以表示所有码位,不需要考虑字符编码过程中的复杂情况;而 UTF-8 由于单个码位可能对应于多个码元,在对文本数据按照字符进行索引时可能会比较麻烦
- 空间占用:UTF-8 相对而言能够非常好地节省文本数据占用的内存,尤其是大量使用 ASCII 字符的文本;而 UTF-16 或 UTF-32 对于部分场景可能会带来两倍甚至是 4 倍的内存膨胀
- 平台支持:Java 标准库、运行时中的字符串和相关的 API 均使用 UTF-16 来对字符数据进行编码;编辑器实现如果需要利用现有的基础设施,那么采用 UTF-16 可能是一个非常好的选择
但 UTF-16 终归还是需要处理 Surrogate 带来的码元和码位的不一致问题,而仍然会带来一部分空间开销,所以直接使用 UTF-8 在很多时候都是一个非常不错的选择。
字符序列维护
在知道了文本数据的表示后,我们再来看下一个问题:我们该如何维护(CRUD)编辑器内部的文本数据?这种文本数据类似于一个 String 或者说由码位组成的序列,而且会被经常性地修改,这些行为的接口可以简化为:
interface TextData {
void edit(Range range, String replacement);
}
那么该如何支持这些修改和查询操作呢?复习数据结构时间
动态数组
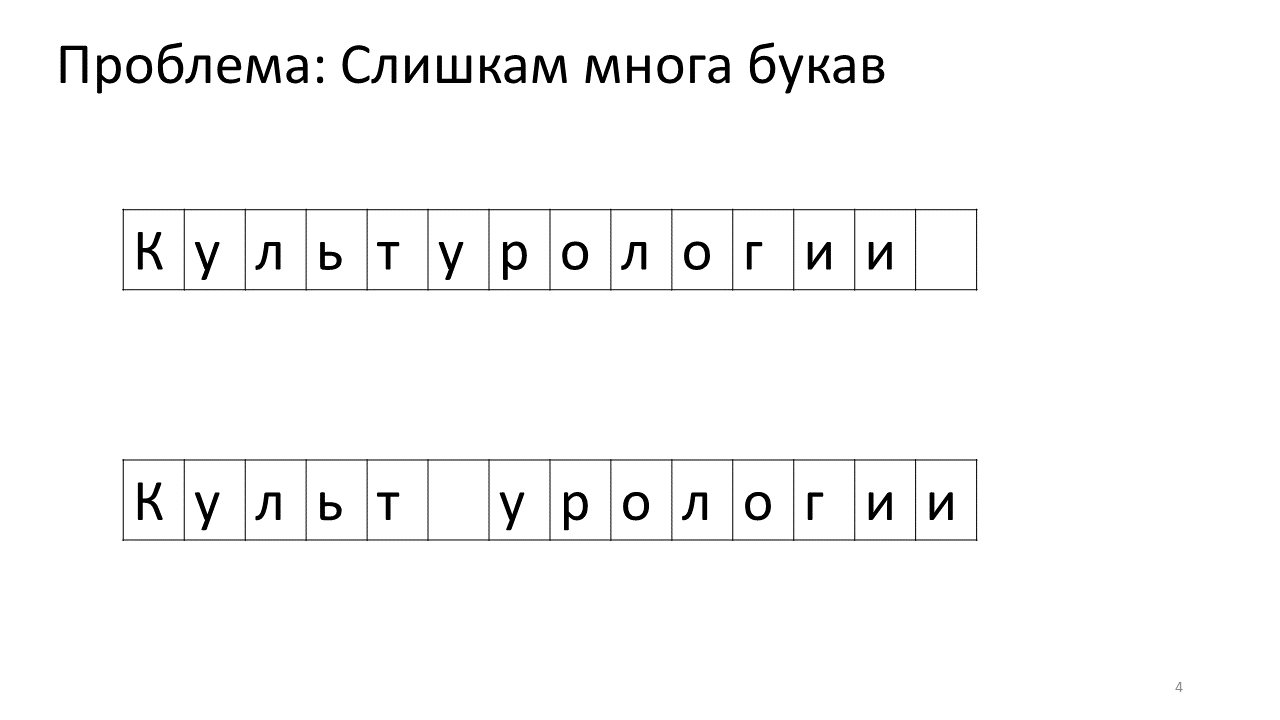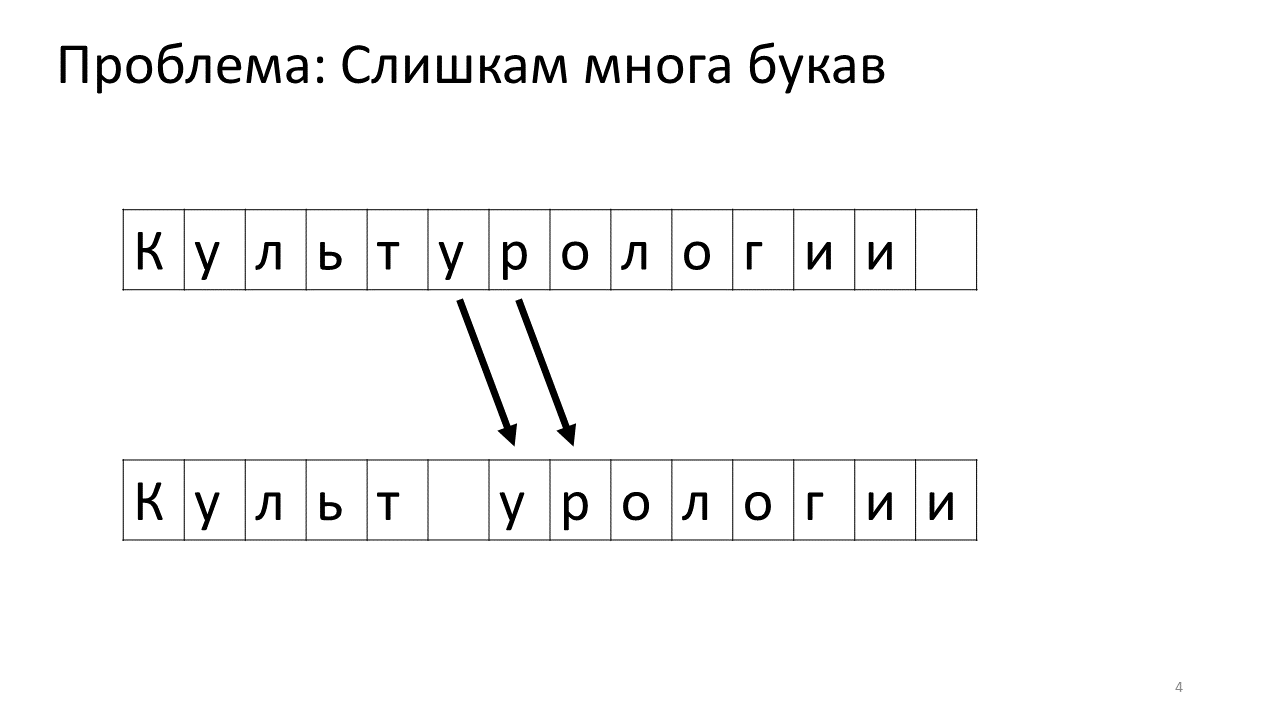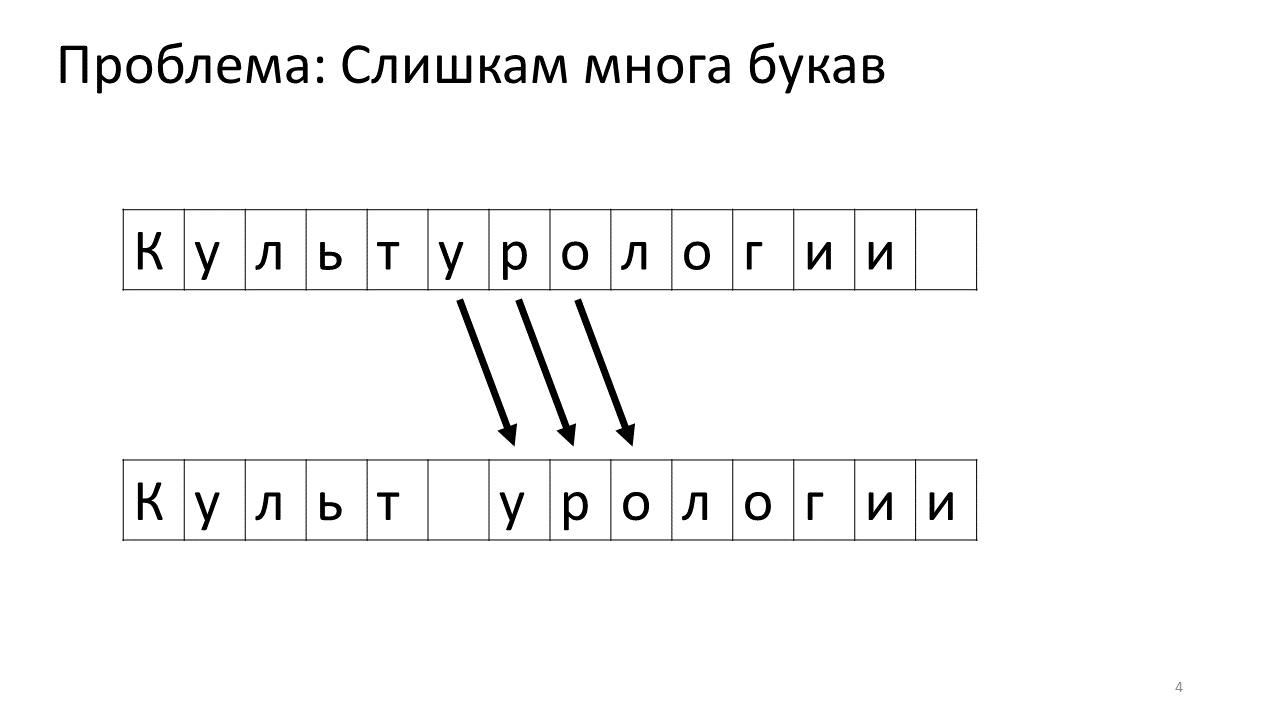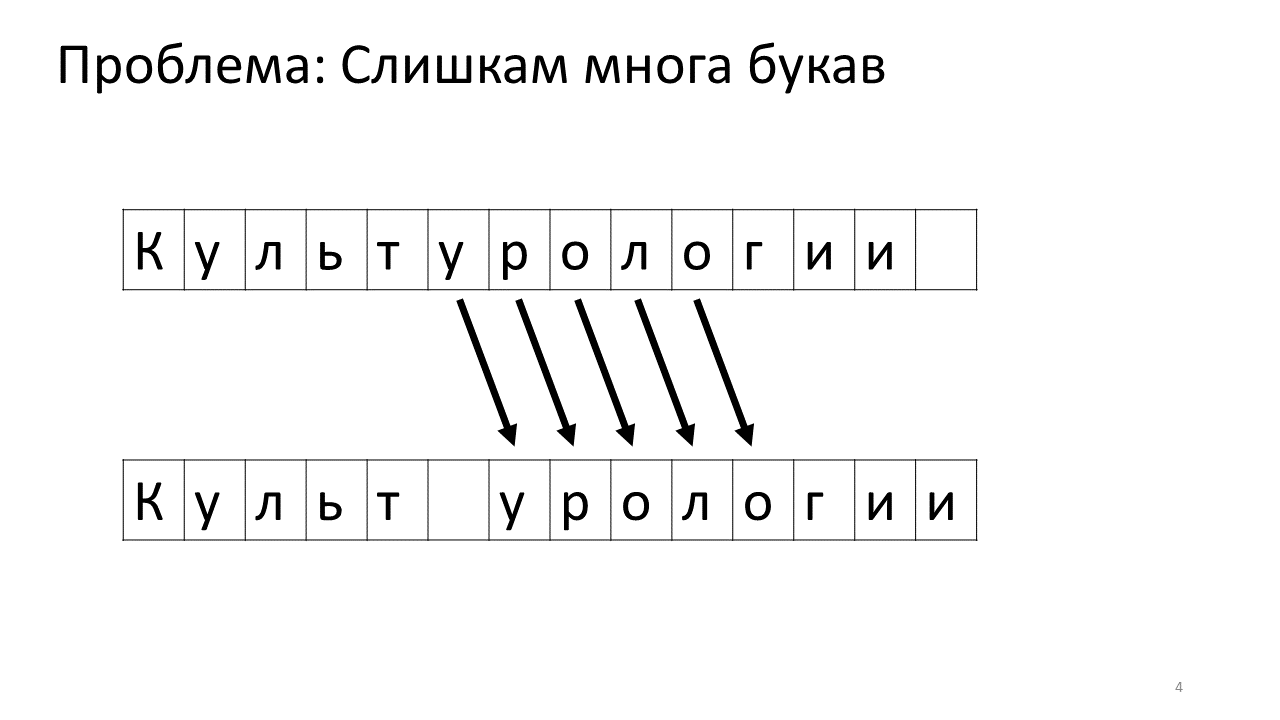
最简单的方法就是使用动态数组了:当发生插入和删除时,直接将位置受到变化的区域的内存进行拷贝即可。而且查询也比较简单,访问数组对应的位置即可。
当然问题也很明显:修改的时间复杂度是 $O(n)$ 的,对于可能频繁发生的编辑操作,每一次修改可能都需要对大量的内存进行拷贝,不适合作为一个对性能有要求的编辑器内部数据结构实现。
Line Set
考虑到文本一般是以行为单位进行展示的(行的定义我们后面再说),我们实际上可以把文本按照行的形式进行存储,每一行单独使用一个动态数组进行维护。当编辑行为在行内时,我们就能以非常低廉的代价完成一次修改了。
这种看上去很朴素的实现实际上已经能够应付大多数文本编辑场景了,不过我们还是希望能够尽量避免遇到它仍然是 $O(n)$ 的修改最坏时间复杂度
Gap Buffer

类似 Line Set,考虑到文本编辑的局部性,我们实际上可以通过一个缓冲区(这里叫做 Gap)来对用户的编辑行为进行加速。
Gap 是存在于文本数据中的一段空缺,实现时通常用两个游标来表示
- 在光标移动并发生编辑时,Gap 两侧的数据会进行移动来调整 Gap 的位置。
- 在光标位置的插入可以直接在 Gap 里填入,Gap 被填满则需要重新分配 Gap
- 对于文本的查询需要考虑 Gap 带来的影响
在对文本进行查询时,如果询问区间跨越了 Gap,那么需要将 Gap 两端的文本拼在一起后得到最终的结果。
Gap Buffer 实现简单、在文本编辑行为的局部性较多时的性能比较好,但在扩展性以及对于大文件的编辑下的表现可能并不理想。
Piece Table
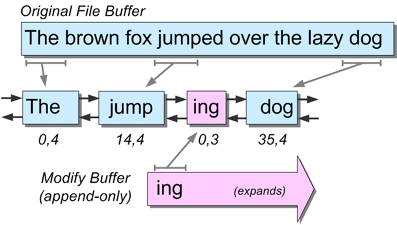
Piece Table 设计时就考虑到了对于大文件的支持,它的假设是:
- 用户的编辑相对于原始的文本数据而言较少
- 用户曾经删除过的内容可能还需要被使用
Piece Table 使用了两个 Buffer 来保存所有参与编辑的文本:
- Original Buffer:对应于起始状态下的编辑文本,只读
- Add Buffer:对应于后续进行编辑时添加的文本,可以读以及 Append
而“Piece Table”中的 Piece 则是对于 Buffer 中一段内容的引用,包括偏移量以及长度。在打开一份文本文件后,我们会创建其所有内容对应的 Original Buffer,和一个包含了此 Buffer 所有内容的 Piece 作为初始 Piece。
Piece Table 会维护一个由 Piece 组成的序列:当对文本进行编辑时,我们会在 Add Buffer 中添加相应的文本,然后对现有序列中的 Piece 进行修改/删除、并插入新添加的文本对应的 Piece。

Visual Studio Code 在 Piece Table 的基础上通过平衡树来维护 Piece 的大小计算并支持区间插入删除等操作,从而使得所有编辑操作都能获得非常好的性能($O(\log n)$)。
但我们也很容易发现,Piece Table 缺乏一些内置的 GC 机制,来处理已经过时的编辑内容,这会导致文本的编辑占用的资源会越来越多,这些问题都需要在实际的编辑器实现中进行考虑。
Rope
一般而言,我们说的 Rope 是指:一种针对字符串这种数据源进行单独设计的 不可变(Immutable)平衡树。
- 文本数据保存在叶子结点中
- 不可变数据结构、支持高效的分裂和连接

Rope 结点分为两种
- 叶结点:拥有一段文本的引用,它所对应的文本就是它持有的文本引用
- 非叶结点:拥有若干子结点,它所对应的文本时它的子结点的文本按顺序连接起来的结果
在 Rope 结点上会保存一些长度信息(左子结点的长度或者本结点)用来对文本进行定位,而考虑到树形结构维护的序列信息的特性(空序列能够生成一个幺元,而非叶子结点对应于信息之间的二元运算),我们还能够在 Rope 上保存很多额外数据,例如序列中的码位个数、换行符个数等等。
作为不可变数据结构,Rope 的修改往往也是以 Copy-on-write 的形式实现的;而实现所有变更的最基础的两个能力就是 Split 和 Concat
- Split:从某个位置把 Rope 切分为两个 Rope
- Concat:将两个 Rope 连接成为一个 Rope
而文本替换则可以通过两次 Split 和两次 Concat 得到相同的效果:
Rope edit(Rope source, Range replaceRange, Rope replacement) {
Rope part1 = source.split(replaceRange.begin).first;
Rope part2 = source.split(replaceRange.end).second;
return concat(part1, concat(replacement, part2));
}
虽然说 Rope 的非叶节点可以直接当作 Concat 的实现,但这样形成的 Rope 可能会不平衡,所以 Concat 里一般还会有相应的重平衡动作,来保证各操作的时间复杂度维持在 $O(\log n)$。一种比较简单的方式为:
- 判断左右结点是否存在一方的总长度大于对方的两倍
- 如果大的一方为非叶子结点同时能够在旋转后使根节点满足此要求,则进行一次旋转
- 对旋转后生成的新结点继续执行 rebalance
Rope 与 Piece Table
Rope 和 Piece Table 实际上在思路上非常相似:
- Piece Table 使用了手动保存的文本 Buffer,并维护 Buffer 上的引用作为间接的文本表示
- Rope 通过叶结点来保存实际的文本 Buffer,并通过 Rope 树对于结点的引用来作为间接的文本表示
同样是引用在某处保存的文本,Rope 可以通过垃圾回收机制对失去引用的 Rope 结点进行回收,这使得在更频繁的文本变更后,Rope 可以清除掉不再使用的文本数据。
Rope 的使用也比 Piece Table 要灵活许多:作为不可变数据结构,它的快照创建是零开销的,这使得撤销和重做非常容易实现;不可变的特性在并发访问时也能避免很多问题。
上面对于文本数据结构的讨论基本上避开了对于编码的处理,然而在实际的编辑器实现中文本数据结构需要支持各种数据之间的转换:例如码元偏移量与码位偏移量之间的转换,同时也需要保证编辑行为不会发生在组成单个码位的多个码元之间。
在下文中提到偏移量时主要是用来表示文本数据结构中用来定位的某种索引类型,可以是码元偏移量也可以是码位偏移量
文本的展示
我们讨论了如何维护编辑的文本数据,并获得了一个能够高效地修改和访问的字符序列。那么如何把这个序列以合理的形式展示在编辑器作为 GUI 程序的二维平面上呢?
折行
一般而言,如果希望文本能够在二维平面上合理地进行排布(而不是依赖横向滚动条),我们会将文本在合适的地方进行分割成若干行,并将这些行从上到下依次排布。
在这些合适的位置添加的东西就是 折行,它分为 硬折行 与 软折行。
- 硬折行是在文本中人工添加的折行,也就是我们常说的“换行符”,表明文本排版应该在此另起一行。虽然叫换行符,但它并不一定是对应于单个字符,而是对应于一个字符序列。
- 软折行是在文本的展示排版过程中自动添加的折行,当文本无法继续在可视区域内排布时,排版软件需要在合适的地方添加软折行,使得后续文本能够继续显示在可视区域内。
目前主流的计算机系统主要使用下面三种换行符:
- Unix 和 类 Unix 系统等: LF(0A)
- Microsoft Windows、MS-DOS 等:CR LF(0D 0A)
远古时期的计算机,为了适应现有的硬件,它们的文本输入系统采取了打字机里的换行机制:
- 使用 Carriage Return 将光标移动到屏幕的最开始
- 使用 Line Feed 将页面向下移动一行
后来的一些系统(MS-DOS 以及之后的 Windows)为了兼容之前的数据以及应用,至今仍然在采用 CR + LF 表示换行的形式。
根据换行符分割出来的文本我们把它叫做 逻辑行(在排版中也可以叫做 Paragraph),这也使得每个码位都拥有了对应的逻辑位置,其中包括:
- 逻辑行号:在此码位前出现过多少个换行符
- 逻辑列号:此码位是其所在的逻辑行的第几个码位
编辑器在进行渲染和交互时经常会需要计算逻辑位置和偏移量之间的转换。为了保证这种转换过程的效率,一般会维护文本中所有出现过的换行符位置,再通过二分查找等方式计算。(对于 Rope 而言我们可以直接在结点的序列信息上添加换行符数量来降低代码复杂度和维护开销)。

与硬折行不同,软折行是排版过程中自动添加的折行,它只会影响文本的布局位置而不会对文本数据本身产生影响。当逻辑行中的文本在编辑器的水平空间无法全部排布时,编辑器需要在合适的地方添加一个软折行(具体的合适流程会在后面详细讲解),使得软折行后的文本在新的一行里继续进行排布。在经过软折行后(但不限于由于软折行导致)的文本的行我们一般称为视觉行(因为在视觉上它们属于同一行)。
文本布局
在获得文本中的逻辑行之后,该如何把逻辑行内的文本数据展示到编辑区域上呢?
这里我们就必须要讨论,看到的文本 和 文本数据 是如何联系起来的。
在 Unicode Text Segmentation 中,我们看到的单个字符 被叫做 “用户感知字符(user-perceived character)” 或者 “字素簇(grapheme cluster)”,原文中是这样描述的:
需要注意的是,用户认为的字符、或者说书写系统中的一个基本单元,可能并不对应于一个 Unicode 码位,而有可能由多个码位组成。为了与这个容易混淆的“字符”概念所区分,我们把它称为用户感知字符。例如字母“G”加上一个重音符号就对应于一个用户感知字符(因为大家可能把它当做一个字符进行书写和阅读),而它实际上由两个码位组成。这种用户感知字符可以粗略的被叫做一个字素簇。
从码位组成的序列——文本数据,到它们各自形成的字素簇,这个过程对于文本的排版、编辑器的交互甚至是暴露的查询 API 而言都是至关重要的。因为在字素簇中不会出现任何对于文本的分割,即:
字素簇是进行文本交互中的原子单位
字素簇与字形
每个字素簇由一个基字符和一系列可能的结合字符组成,在不同的字素簇之间存在字素边界,光标一般只能出现在字素边界处。在同样的一篇文档中(UAX#29),定义了根据码位来计算字素边界的方式,具体规则极其复杂。不过好在大多数语言都有现成的库来完成这种任务,我们这里就不再继续讨论。
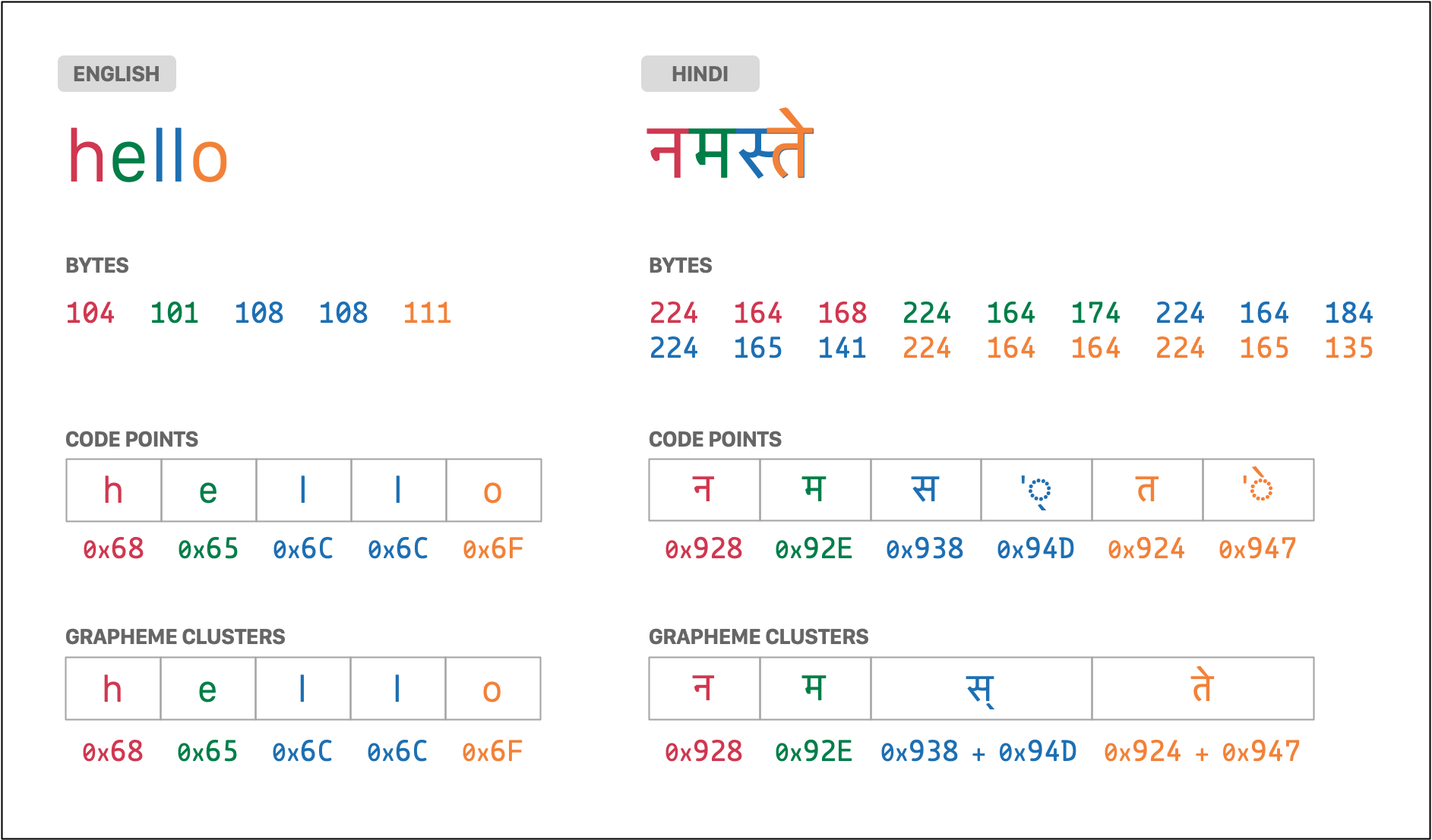
虽然字素簇是文本交互中的原子,但并不代表它一定能在渲染的文本中找到独立的一个图形作为该字素簇的表示,字素簇与最终渲染的图案(我们叫做字形)之间可能拥有者极为复杂的多对多关系。
那么我们该如何根据字素簇获得这些字形呢?
字形的正确处理需要来自字体和文本定形引擎(Text Shaping Engine)。
字体文件里会包含一系列的字形(例如字母、数字、符号等,它们拥有独一无二的 ID),以及一个将码位映射到字形 ID 的表。而文本定形就是指把一系列码位映射到正确的字形 ID 并生成一些额外数据的过程。
文本定形中需要解决的一个问题就是连字(Ligature)。它指的是两个或更多的相邻的字素在展示时使用单个 字形(glyph)的一种字体排印学现象。常见的例子包括:

连字的实现需要文本定形引擎和字体的支持,字体文件中会保存连字相关的映射表;而引擎需要根据传入的文本,找到所有匹配的连字,并根据语境来对结果进行取舍。(例如阿拉伯文中的一个字符根据在文本中不同的位置会对应四种不同的字形)
另一种会对字形产生影响的特性则是组合字符(composing character)

字体会提供组合字符附加在基字符上的字形,并由文本定型引擎来计算出字形相对于基字符所在的字形的偏移量,从而得到最终的文本字形。
双向文本排布
那么是不是直接把从码位生成的字形从左到右依次排布在编辑器里就行了呢?当然没有这么简单。在某些语言的文字中,它们是按照从右至左,从上到下的顺序进行书写/阅读的,常见的语种包括:阿拉伯文、希伯来语、波斯语等。
如果在一个逻辑行中仅仅拥有同一个方向的文本,那么这个问题很好回答:只需要把它们按照各自的方向进行排布即可;但如果同时出现了从左至右和从右至左的文本时该如何处理?
这时候我们就需要引入 UAX#9 中的双向文本排布算法了(以下简称 Bidi 算法)。

Bidi 算法一共分为四个部分:
- 分段:将文本切分为需要进行实际的 Bidi 计算的段落,即上文中的逻辑行切割
- 初始化:提取出文本中字符的 Bidi 类型并赋予一个初始的 Embedding Level
- 计算:根据 Bidi 计算规则调整每个字符对应的实际 Embedding Level
- 重排序:将每一段文字中的字符根据上一步骤得到的 Embedding Level 计算出实际的显示顺序
对于所有的 Unicode 字符,都有一个对应的 Bidi 类型。当具有不同 Bidi 类型的字符混排在一起时,Bidi 算法会根据规则以及字符的 Bidi 属性计算它们的 Embedding Level。Embedding Level 是 Bidi 算法中用来描述一段文本的朝向和嵌套深度时使用的,它用一个在 0~125 之间的整数来表示。其中偶数对应于 LTR 文本,奇数对应于 RTL 文本。正常的 LTR 文本是 0,而下面这段文本中引号里的内容则是 1 :he said “ٱٹ!ڃ” to her。对于一段最长的拥有相同 Embedding Level 的字符序列,我们把它称为一个 Bidi Run。根据 Embedding Level 的性质,我们知道每个 Bidi Run 内部的文本会在排布时拥有相同的朝向。
在 Unicode 字符集中,某些字符一定需要按照其期望的方式进行排布,这些字符对应于强 Bidi 类型。对于强 Bidi 类型的字符,Bidi Run 的计算相当简单,只需要把具有相邻的相同朝向的文本聚合在一起即可。
而某些字符的朝向则与其上下文有关,它们的 Bidi 类型为中立 Bidi 类型或弱 Bidi 类型。对于这些字符,情况则会变得相当复杂。
中性 Bidi 类型的字符(例如空格,标点符号等)在排布时的规则为:
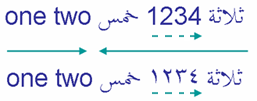
- 当(一连串)中立字符处于两个具有相同方向的强方向字符中间时,该字符会呈现出同样的方向性(即最终会在同一个 Bidi Run 中)。例如下图中每个 Bidi Run 里的空格字符:

- 当中立字符处于两个具有不同方向的强方向字符中间时,该字符会呈现出嵌入等级更低的方向性。例如下图中的阿拉伯文后的逗号:

而弱 Bidi 类型的字符,例如数字,它们会和周围的强 Bidi 类型的文本属于同一个 Bidi Run;但它们本身的展示顺序是和它所在的 Bidi Run 无关的,即弱 Bidi 类型的字符不会打断当前的 Bidi Run
Unicode 中也包括了一些能够对 Bidi 算法产生影响的控制字符,这里我们用一个例子看看它们的作用,其中 >、<、= 分别对应于 LRI、RLI 和 PDI,大写字母对应于强 RTL 字符,小写字母对应于强 LTR 字符。
Storage DID YOU SAY ’>he said “<car MEANS CAR=”=‘?
Resolved levels 111111111111112222222222444333333333322111
Reverse level 4 DID YOU SAY ’>he said “<rac MEANS CAR=”=‘?
Reverse levels 3-4 DID YOU SAY ’>he said “<RAC SNAEM car=”=‘?
Reverse levels 2-4 DID YOU SAY ’>”=rac MEANS CAR<“ dias eh=‘?
Reverse levels 1-4 ?‘=he said “<RAC SNAEM car=”>’ YAS UOY DID
Display ?‘he said “RAC SNAEM car”’ YAS UOY DID
首先根据文本内容判断最外层的 Embedding Level 为 1,然后根据控制字符找出其中的 Isolating Run Sequence,并调整其中字符的 Embedding Level;在计算完所有字符的 Embedding Level 后,依次将各个 Level 所包含的文本进行翻转,并产生最终的 Bidi 结果。
对于代码编辑器而言,我们希望作为代码的文本能够在展示时维持其作为代码的语义,所以代码编辑器在进行双向文本排布时会将一个词法单元而非逻辑行作为进行双向文本排布计算的基本单元,从而避免由于 Bidi 控制字符而导致符号的显示语义发生变化:例如在 Right-to-Left Override 符号后的 a > b 很有可能会显示为 b > a。
不过即便如此,代码里的 Bidi 逻辑仍然可能会带来一些麻烦,例如去年 11 月有人提出了由于 Trojan Source 导致的安全问题。所谓的 Trojan Source 就是指通过不可见的 Unicode 控制字符来改变文本的渲染结果,使得包含漏洞的代码能够通过代码审核人员的检视:
int main() {
bool isAdmin = false;
/* } if (isAdmin) begin admins only */
std::cout << "You are an admin.\n";
/* end admins only { */
return 0;
}
上面这份代码实际上等效于下面这段代码(其中 RLO/LRI/PDI 均为 Bidi 控制字符):
int main() {
bool isAdmin = false;
/*RLO } LRI if (isAdmin) PDI LRI begin admins only */
std::cout << "You are an admin.\n";
/* end admin only RLO { LRI */
}
RLO 覆写了其后文本的 Bidi 属性,而 LRI 和 PDI 则创建了一个独立的 LTR 文本块,从而使得从大括号开始的文本进行翻转,并对于 if (isAdmin) 和 begin admins only 这两块文本分别再次进行翻转,从而得到使两份文本交换顺序的视觉效果。
在该漏洞被提出后,主流代码编辑器都纷纷把默认的“渲染控制字符”设置为了是,从而减少这种排版问题影响语义情况的出现。
软折行
在计算完各个 Bidi Run 的内容和顺序后,我们便能够在一个无限大的二维平面上渲染出正确的文本内容了。但很多时候用户并不希望使用横向滚动条在这个二维平面上进行检索,这时候就需要使用软折行来将文本排布到有限长度的横向空间中。
软折行的添加会使得逻辑行中视觉顺序位于其后的元素在新的一个视觉行中进行排布。那么在什么地方能够添加一个软折行?
- 除非单词长度无法在编辑器宽度中放下,否则我们应该始终在“单词(Word)”的边界上添加折行。
其实不止是软折行,很多与单词相关的编辑行为都会被单词的定义所影响,例如双击文本来选中一个单词、Ctrl + 方向键的基于单词的光标移动。单词的定义根据文本类型的不同会有一些区别,不过我们一般而言还是会以符号、空白字符等特殊字符作为单词的分界(在不考虑对中文分词进行支持的情况下)。而对于长度超过宽度限制的单词,我们在排版之前先根据其中的字素边界,将单词分割成多个满足宽度限制的片段,再进行软折行的计算。
回答完第一个问题,我们再来思考:我们应该在什么地方添加?
对于折行的结果,通常会根据两个指标进行优化:
- 最少化添加的软折行数量
- 最少化不同行之间的参差(软折行会导致不同行里的非空白字符密度不同)
Knuth 在他的 TeX 排版引擎里一个很重要的工作就是提出了针对于第二个指标进行优化的排版算法,通过动态规划获得了非常好的排版结果(有兴趣的同学可以去看一下这篇文章)。
但对于我们常用的所见即所得的文本编辑器而言,采取以第一个指标进行优化的方式可能就已经足够了,而且实现一个简单的贪心算法就足以满足需求:
SpaceLeft := LineWidth
for each Fragment in Text
if (Width(Fragment) + SpaceWidth) > SpaceLeft
insert line break before Fragment in Text
SpaceLeft := LineWidth - Width(Fragment)
else
SpaceLeft := SpaceLeft - (Width(Fragment) + SpaceWidth)
总结
今天我们简单地科普了一下大家常用的代码编辑器里的一些细节,包含编码、字符序列维护和文本排版的小知识。碍于篇幅所限,和代码编辑相关的细节会放在《代码编辑器如何工作的?(下)》里,敬请期待。
引用
Unicode Character Encoding Model
Introduction to Character Encoding
Introduction to Character Set and Character Encoding For WordPress Users
Data Structures For Text Sequences - Charles Crowley
Piece Table in Visual Studio Code
Text editor - this is not your highest mathematics, then you have to think
Unicode Bidirectional Algorithm basics